


俗话说“工欲善其事,必先利其器”,对表观遗传研究感兴趣或即将从事表观遗传研究的你,可能需要对表观遗传研究的常用工具有个初步了解。本文根据 2016 年 8 月在复旦举办的「表观基因组学暑期国际讲习班」中的《第八讲 表观遗传学常用软件及网站资源介绍》视频整理而成。
本期主讲人为复旦大学生物医学研究院青年研究员李伟,主要讲解了 UCSC Genome Browser 的使用、简要介绍了 Roadmap 数据库及 RNA-seq 数据的处理流程,分享了表观遗传领域常用的数据库。
ChIP-seq 的分析由同济大学张勇老师在《第十五讲ChIP-seq 及 DNA 甲基化分析策略》中详细讲解,我们后续将推送,请持续关注。李伟,生物信息学博士,复旦大学生物医学研究院青年研究员;主持国家级课题两项,以主要参与人身份参与国家精准医项目、国家 973 项目、国家自然科学基金项目、上海市科委重大基础项目 9 项;以通讯、一作身份及主要参与人身份发表 SCI 论文 12 篇。以下是正文:生物信息学是干什么的?这是不是一个“高大上”的东西?我本科不是学计算机、数学的,能不能做生物信息?答案是可以的。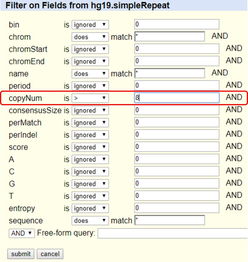
我本科就是做实验的,到了研究生阶段才开始涉猎生物信息学的东西,我觉得我能做到,你们也可以,所以大可不必担心。
生物信息学是什么?生物信息学(Bioinformatics)利用应用生物学、数学、 信息学、统计学和计算机科学的方法研究生物学的问题,是分子生物学与计算机科学的结合体。它要求做生物信息的人员有足够的生物学、数学、信息学、统计学和计算机学背景。为何涉及到这么多学科?因为生物学的问题并不是“非零即一”的,总有例外存在。
如果没有生物学背景的话,总认为答案是“是”或者“不是”;但事实上,生物问题没有绝对的“是”或“不是”,所以生物背景很重要的。那数学、信息学、统计学背景有什么用呢?我们在实验上产生了很多的 seq data,有时候是几个 G,大量样本都是几个 T 的,如果你没有统计学、信息学和数学的基础,是没有办法把这些海量的数据筛成你感兴趣的部分的,所以这个部分是必要的。
除了筛选数据,还有就是我们怎么评价获得的数据?举个很简单的一个例子,我们拿样本去公司做 RNA-seq,做完以后公司给你出了一个报告,马上就会说“那你付钱吧”。
那我要不要去付钱?怎么评价公司给我的 RNA-seq data 是不是对的呢?生物信息学可以帮助你很快地把拿到的 data 进行初步的筛选和分析,来确认在公司的环节是否存在问题。为什么后期还要有一定的计算机背景呢?生物学是必须具备的,另外那几个方面,至少在我们研究的相关领域里面,需要懂得很多的方法。计算机呢,并没有要求大家精通,毕竟我们不是程序员,我们的目的是把我们想实现的东西实现出来就 OK 了。
如果说你做算法优化的话,那需要你有一定的计算机基础,因为任何一种算法都要考虑到它的时间和空间开销。如果你是做初步的分析的话呢,我建议这些学科你要都有涉猎。生物信息学呢,就是这么多学科的一个 mix。生物信息学在表观遗传领域里面的应用,还是依据表观遗传学的分类的,包括 DNA 甲基化修饰、组蛋白修饰,还有非编码 RNA 的调控,在我的 section 里面呢,我会从下面的三个部分来帮助大家走进生物信息学。
第一部分:ENCODE 及 Roadmap 数据库的介绍。我们做表观遗传的时候可能都会涉及到这两大计划,这两大计划耗费了很多钱和人力来完成。我们怎样能更好地使用和浏览这两大计划里面的一些数据和数据库。我会提供 UCSC 王艇老师(圣路易斯华盛顿大学教授)组开发的一个 server 工具,帮助大家合理地使用和浏览这两大计划产生的数据。
其实很多人认为这两大计划产生的数据就足够的。第二部分:RNA-seq 数据获取及分析流程。RNA-seq 我会给大家大概讲一下,怎么从网站上下载一些别人已经测过的或者 paper 已经发表的 RNA-seq 数据。当我拿到了别人的数据以后,我应该用哪些流程来评估和分析这些数据,因为表达数据我们大部分研究都是要用到的;还有就是 RNA-seq 里面现在有一些主流的分析套路,包括 TopHat、TopHat2 等。
2016 年 5 月还出了一个新的方法,文章里评估它的性能不输于 TopHat2,我会把它的 map 原理分享给大家。最后一部分:表观遗传学常用数据库介绍。这部分我展示的时间并不长,我会依据表观遗传学不同的分类,每个部分推荐大家几个常用的数据库,包括里面也有我自己写的 server。
看的时候,我通常会把这些网站归为两类:一类是“淘宝”类的网页,一类是需要一定的编程基础的。所以第三个部分,我推荐给大家的基本都是“淘宝”类的网页,点按式的,界面都很友好的。大家记住都有哪些资源,就 OK 了。
PART 1: UCSC 及 Roadmap 数据库的介绍UCSC 数据库:一个存储 ENCODE 计划数据的数据库。如果你做 seq data,不管你是做实验的还是做信息学分析的,你都会用到这个 UCSC 数据库。这里面我会展示几个常用的板块。UCSC 简介:1. 给浏览基因组数据提供了可靠和迅速的方式。
2. 数据来源:约有一半的注释信息是 UCSC 通过来自公开的序列数据计算得出,另外一半来自世界各地的科学工作者。3. 本身并不下任何结论,只是收集各种相关信息供用户参考。4. 支持数据库检索和序列相似性搜索。
UCSC 网页上面有各种工具,我会给大家简要地介绍一下其中的五个。Genome Browser图 2. Genome 板块的界面这个页面的每个部分,都很容易看懂。在 Position/Search Term 这可以输入一些基因名字,比如说我随便输入一个BRCA1,它是乳腺癌里面很有名的一个基因,它立刻出现不同的 isoforms,还有一些 non-coding 的 isoform 形式。你可以根据关注的基因组位置,来 filter 这些结果。
图 4.BRCA1基因在 Genome Broswer 中的可视化上面的可视化部分,行包括基因组的 backbone、STS (Sequence-tagged site)marker、不同的 isoform,还有参考基因组。我选的是人类的 mRNA,还有一些同源物种的,因为有的人是做进化的,需要做不同的同源物种,还有 ESTs、保守性(conservation),保守性我等会有一张专门 slide 告诉你这里面不同的颜色、不同的框、不同的形状代表的是什么。图 6. 序列保守性中不同颜色和形状的具体含义上图中左侧显示的是不同的物种,图中单线条表示上面是没有序列(碱基)的。
如果某一段 mark 上了浅黄色,说明它的保守性方面还没有报道,数据库里面没有备注。保守性的高度和颜色深度,代表它保守性的强度。它的高度越高颜色越深,它的保守。















