文章目录
- 🌟项目介绍前言
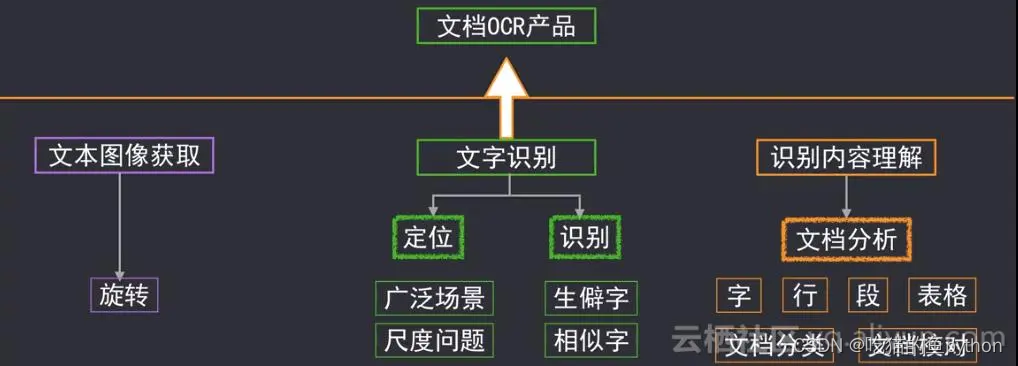
- 🌟文档识别步骤简介
- 🌟项目图像处理步骤详细介绍
- 🌟项目OCR识别操作介绍

🌟项目介绍前言
我们在日常生活或者办公中,可能都使用过万能扫描王这个软件,或者qq中的照片文字扫描功能,然后直接利用扒下来的文档直接复制粘贴直接使用,那么他这个原理是什么呢?又是怎么用OpenCV来实现的呢。我们这次博客就来全面介绍一下这个整体流程。并进行真实案例操作。
🌟文档识别步骤简介
我们要完成对于文档图片的扫描工作。大致流程主要步骤分为以下几个步骤。

1. 图像边缘检测。
2. 获取轮廓信息。
3. 透视变换,经过旋转、平移等操作对文档图片进行处理。
4. OCR识别图片当中每一个字符。
🌟项目图像处理步骤详细介绍
首先我们要对两个文件进行处理,我们先来看一下预处理的图片什么样子。



我们这里以一个英文的文件,一个自己用中文的一首诗来去做这个项目。因为怕其他东西干扰边缘,于是自己画了个框把边缘圈起来了。
首先我们还是要导入第三方库,然后获取参数。
import numpy as npimport argparseimport cv2ap = argparse.ArgumentParser()ap.add_argument("-i", "--image", required = True, help = "Path to the image to be scanned") args = vars(ap.parse_args())这里我们一定要会这种导入参数的形式,非常方便,后期设置参数也非常方便,指定路径就完全OK了。
这里我们只需要指定一个传入参数,原始图像就OK了。
然后我们使用DEBUG操作一步一步进行操作,首先我们对图像进行一个resize操作。
image = cv2.imread(args["image"])ratio = image.shape[0] / 500.0orig = image.copy()image = resize(orig, height = 500)首先我们读取image数据,然后对图像进行一个求比例的操作。后期会用得到,再对图像进行resize操作时候,我们会把图像的h和w设置成同一比例。这里我们对image进行了resize函数操作,那么resize函数是什么呢?我们继续看。
def resize(image, width=None, height=None, inter=cv2.INTER_AREA): dim = None (h, w) = image.shape[:2] if width is None and height is None: return image if width is None: r = height / float(h) dim = (int(w * r), height) else: r = width / float(w) dim = (width, int(h * r)) resized = cv2.resize(image, dim, interpolation=inter) return resized上方我们传入resize函数的参数是orig, height = 500,那么orig是原始图像的copy,因为取轮廓是不可逆的,所以我们用copy去做,这里我们提取到图像的h和w,因为我们设置了height所以直接跳到if width is None,比例r=height/float(h),为了把width设置成和height同比例,所以进行了dim = (int(w * r), height),完成之后呢,就把dim传入到cv2.resize(image,dim,interpolation=inter),这里就把图像进行了同比例的resize操作。完成之后呢我们继续DEBUG继续看。
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)gray = cv2.GaussianBlur(gray, (5, 5), 0)edged = cv2.Canny(gray, 75, 200)对图像进行了形态学处理,分别是颜色空间转换,也就是彩色BGR转灰度,然后,进行了一次高斯滤波操作,可以让原图像模糊,目的就是为了去除噪音,最后计算出边缘信息,阈值设置为75到200。
cv2.imshow("Image", image)cv2.imshow("Edged", edged)cv2.waitKey(0)cv2.destroyAllWindows()展示一下处理之后的结果。
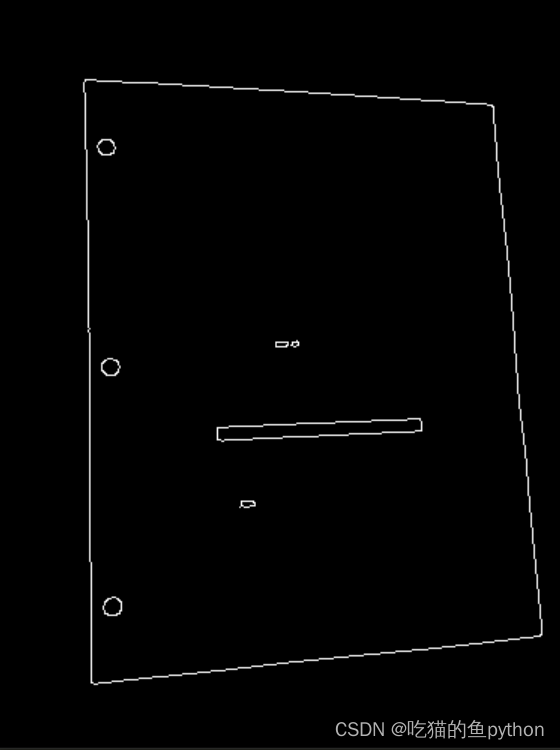


这就是边缘检测之后的结果了,但是边缘检测之后的结果是一个点一个点的,所以我们要进行轮廓的提取。然后我们要进行一个轮廓的提取,我们要对图像中最外面的轮廓进行提取,因为我们要提取文档。
cnts = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]cnts = sorted(cnts, key = cv2.contourArea, reverse = True)[:5]这里我们首先进行了一个轮廓的提取,里面的参数cv2.RETR_LIST表示检测的轮廓不建立等级关系,cv2.CHAIN_APPROX_SIMPLE这里表示只简单的进行提取轮廓,用四个点来展示轮廓。因为这里返回了两个参数,老版本的CV返回的三个参数,但是我们只要轮廓参数就好了。所以设置索引为0,得到轮廓后呢,我们把轮廓按照面积大小进行了排序,由大到小,并且只取前五个。
for c in cnts: # 计算轮廓近似 peri = cv2.arcLength(c, True) approx = cv2.approxPolyDP(c, 0.02 * peri, True) # 4个点的时候就拿出来 if len(approx) == 4: screenCnt = approx break# 展示结果print("STEP 2: 获取轮廓")cv2.drawContours(image, [screenCnt], -1, (0, 255, 0), 2)cv2.imshow("Outline", image)cv2.waitKey(0)cv2.destroyAllWindows()这里cv2.arcLength表示计算轮廓的周长。cv2.approxPolyDP主要功能是把一个连续光滑曲线折线化,其中0.02 * peri表示从原始轮廓到近似轮廓的最大距离,它是一个准确度参数。当轮廓是四个点的时候就拿出来,然后我们进行一个显示。得到的结果是:



接下来就是一个最主要的一个部分,就是透视变换,也就是说我们想把后面的背景全部去掉,也就是想把我们轮廓检测出来的这一块拿出来单独成一个图像,然后方便我们去OCR文字识别。
warped = four_point_transform(orig, screenCnt.reshape(4, 2) * ratio)我们直接跳进four_point_transform函数中。
def four_point_transform(image, pts): rect = order_points(pts) (tl, tr, br, bl) = rect # 计算输入的w和h值 widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2)) widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2)) maxWidth = max(int(widthA), int(widthB)) heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2)) heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2)) maxHeight = max(int(heightA), int(heightB)) # 变换后对应坐标位置 dst = np.array([ [0, 0], [maxWidth - 1, 0], [maxWidth - 1, maxHeight - 1], [0, maxHeight - 1]], dtype = "float32") # 计算变换矩阵 M = cv2.getPerspectiveTransform(rect, dst) warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight)) # 返回变换后结果 return warped首先利用order_points获取坐标。我们可以看到首先设定了rect这个0矩阵,用来传我们的坐标点,按顺序找到对应坐标0123分别是 左上,右上,右下,左下
def order_points(pts): # 一共4个坐标点 rect = np.zeros((4, 2), dtype = "float32") s = pts.sum(axis = 1) rect[0] = pts[np.argmin(s)] rect[2] = pts[np.argmax(s)] # 计算右上和左下 diff = np.diff(pts, axis = 1) rect[1] = pts[np.argmin(diff)] rect[3] = pts[np.argmax(diff)] return rect这里pts.sum(axis = 1)就是把横纵坐标进行一个相加的操作,那么最小的肯定就是左上的点,最大的肯定就是右下。
np.diff(pts, axis = 1)是求diff=y-x, 那么最小的是右上,最大的是左下。这样我们就把轮廓的四个点拿出来了。返回去我们继续看,(tl, tr, br, bl) = rect这里拿到了这四个点。widthA和widthB分别计算矩形上下的边长分别是多少,我们需要选择一个相对更大的,来把整个文件图片框住。heightA和heightB就是对于竖直的两个边进行了判断。然后定义一个转换后的坐标值。然后需要计算一个如何将当前图像转换到定义好的图像,需要计算一个转换矩阵M,然后我们通过使用原始矩阵*M就可以得到处理后的结果了。
然后对于经过透视变换的图进行形态学处理。并且展示结果。
warped = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)ref = cv2.threshold(warped, 100, 255, cv2.THRESH_BINARY)[1]cv2.imwrite('scan.jpg', ref)print("STEP 3: 变换")cv2.imshow("Original", resize(orig, height = 650))cv2.imshow("Scanned", resize(ref, height = 650))cv2.waitKey(0)
这里我们就把整个轮廓给抠出来了,接下来就是识别的操作。
🌟项目OCR识别操作介绍
首先我们先要对OCR文件进行下载:下载地址
用到的是最后一个。或者pip install pytesseract。
导入第三方库
from PIL import Imageimport pytesseractimport cv2import osimage = cv2.imread('scan.jpg')gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)if preprocess == "thresh": gray = cv2.threshold(gray, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]if preprocess == "blur": gray = cv2.medianBlur(gray, 3) filename = "{}.png".format(os.getpid())cv2.imwrite(filename, gray)text = pytesseract.image_to_string(Image.open(filename),lang='chi_sim')print(text)cv2.imshow("Image", image)cv2.imshow("Output", gray)cv2.waitKey(0) 这里就是一些形态学处理,其中包括转灰度,然后进行中值滤波或者二值。最后通过pytesseract.image_to_string(Image.open(filename),lang='chi_sim'),进行输出识别内容。最后一个参数指定语言的。然后显示出来把图像。
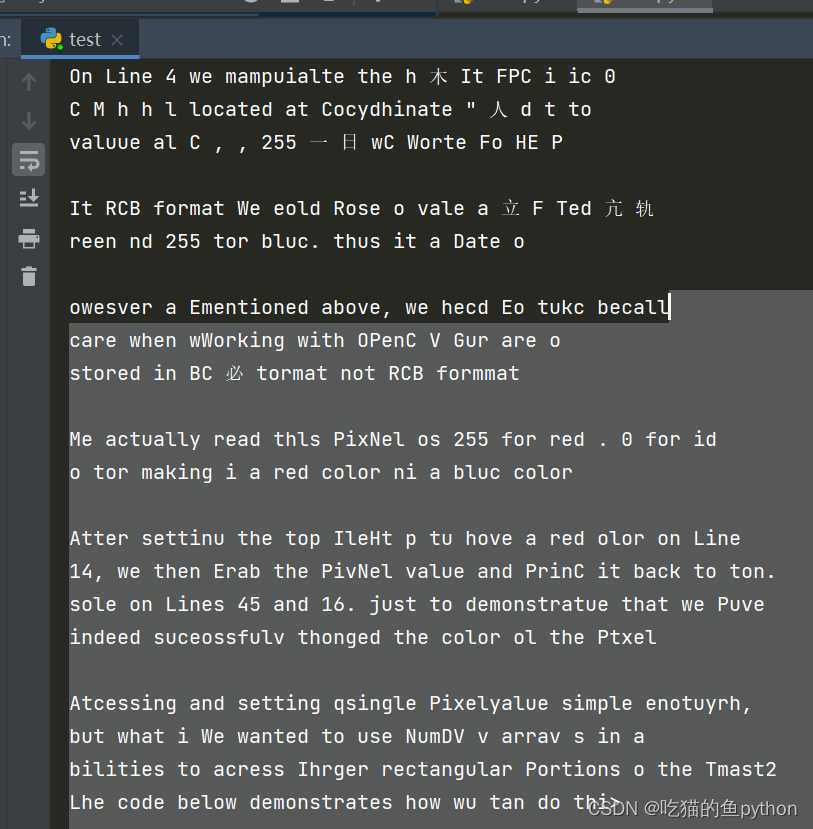

这里可能我写的这个不太规范,我们再找另外一个图测试一下。用了自己的身份证图做了一下,最终得到的结果是:

这里由于隐私进行了遮挡,但是事实证明,这样确实准确率要高很多很多。但是整体来说识别准确度并不特别高,后期我们会继续优化这个程序,期待后续更新吧。

🔎支持:🎁🎁🎁如果觉得博主的文章还不错或者您用得到的话,可以免费的关注一下博主,如果三连收藏支持就更好啦!这就是给予我最大的支持!