


索引!
又见索引!
各位朋友知道,索引几乎伴着所有结构化和非结构数据库出现,就像紫薇格格旁边一定站着丫鬟金锁那样,就看是冰冰伴着心如还是耀琪伴着海陆。每个数据库使用的索引技术都有点像,但又不全像。可以肯定的是,索引的,目标就是为数据主人跑腿,实现更高的查询性能!
言归正传,我们来看看柏睿数据内存分布式数据库RapidsDB的索引是怎么扮演好它的加速功能吧!
RapidsDB的索引包括了3类索引:
第 一类:行存表索引
跳表索引:
RapidsDB中的默认索引类型是跳表索引,对比其他大多数数据库(比如MYSQL)使用的B-Tree索引,RapidsDB将跳表索引优化为在内存中运行,不仅可以实现无锁并提供极快的插入性能,还提供Btree类似的O(log(n))查找性能,非常适合OLTP遍历查询。
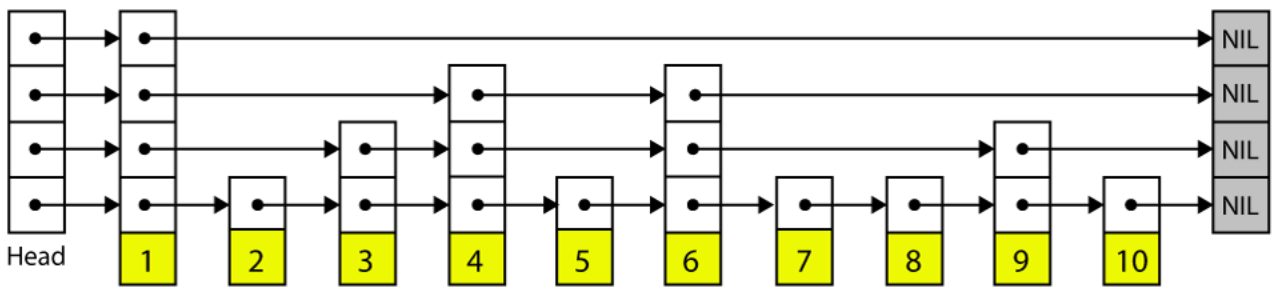
索引使用到的无锁(或者叫非阻塞)算法是跳表索引的一个大特点:它使数据库线程始终可以运行,尤其在多核CPU硬件上实现高并发负载。同时还摆脱了Btrees需要使用复杂的锁定方案来实现线程安全的困局。对BWtree这类比较新的无锁索引数据结构,规避掉被设计远超跳表的复杂数据结构实现无锁。可以说跳表的简单性使其非常适合无锁实现。
哈希索引:
哈希索引在数据库中十分常见。一般情况下,只有当查询对索引中的每一列都使用相等过滤器时,才会使用哈希索引。所以按理说,哈希索引应该只在用户的特定数据集和工作负载有明显的需要和可测量的好处时使用。在这些特定情况下,哈希索引提供了对唯 一值的快速精确的匹配访问。
第二类:列存表索引
列存储索引利用列存储技术高效地从磁盘存储中检索大量值(建议使用闪存或固态硬盘)。因为列存储索引通常提供大量压缩数据,这是由磁盘支持的,不像RapidsDB中的其他类型的索引那样要求所有数据都必须存放于内存中,所以对于时刻处理PB级数据量的分析型工作的负载优化非常有用。
列存索引是将列存表中一列或多列定义为键列。数据按键列顺序存储以提高检索性能。由此引入行段概念,行段是列存索引中存储在一起的一组行,每个行都由列段组成。RapidsDB存储每行的元数据,其中包括给定段的总行数,以及跟踪哪些行已被删除的位掩码。而且RapidsDB会在列存索引键列上的一组行段进行排序。这意味在已排序的行段组中,不会有行段与构成列存索引键的列的值范围重叠。在对表运行 INSERT、LOAD 或 UPDATE 查询后创建更多段时,会形成新的段组。
在以下四种情况下,列存索引对RapidsDB的列存表起明显的加速效果:
✔查询仅扫描索引指定的列段,如测试表Products的索引为Qty,查询 SELECT SUM(Qty) FROM Products;则只需要扫描Qty列段,并且利用列段中的值做SUM计算。
✔查询只引用行段中的列存索引元数据。简单例子:SELECT COUNT(*) FROM Products;使用MAX或者MIN也可以达到相同的效果。
✔查询过滤条件使用列存索引元数据的最 小值和最 大值,判断是否跳过扫描对应的行段。优化效率取决于实际可以跳过的段的百分比。
✔在表关联时,列存索引被用在关联条件时,只需要简单扫描行段的值,就可以完成关联条件的过滤,同样的跳过了IO磁盘扫描的开销,提升性能。
第三类:特殊数据类型索引
全文索引(Full-Text Index):
全文搜索使用逆向索引的方式在大量文本中搜索单词或短语。这类搜索可以是精确也可以是模糊的,目前只支持CHAR、VARCHAR、TEXT和LONGTEXT这几种数据类型。目前对于RapidsDB来说,仅在列存表上支持全文索引。此外,全文索引CREATE TABLE查询的一部分启用。这意味着在创建表后不能删除或更改全文索引。如果表被删除,那么索引会被自动删除。
地理空间索引:
地理空间索引在国内项目中使用得不多,它用存储在保存空间数据的列上,用来定义地理空间索引,并用于加快对它们的查询。地理空间索引使用控制参数值(6-32)对多边形和线型进行切分。数字越小索引使用的内存消耗越小、插入和更新等操作越快,但查询时间就慢。越大的控制参数值则以内存和插入性能为代价来提高查询性能。
在国有大行普惠金融项目应用中,现场使用的都是列存表,柏睿数据对这些表都做了创建列存索引的优化操作,并且按客户要求的深度优化中,通过对业务应用分析,对索引键做响应的调整,获得提升30%到几倍的优化效果。















