


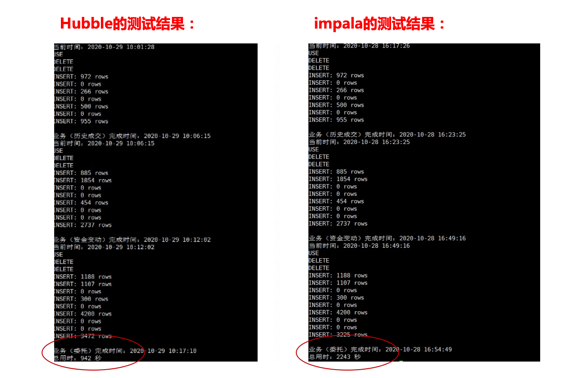
在数据体量121亿条账户下进行资金查询测试,天云数据Hubble的性能是Impala的231%倍。
Impala,一种栖息在非洲南部的高角羚,行动敏捷奔跑迅速,以其优雅的姿势和杰出的跳跃能力而出名。受惊的时候可以跳起 3米高,9米远。
Cloudera研发这头高角羚(Impala)的初衷也很明了——提高Hive SQL查询的速度。就官方测试性能来看,Impala比Hive快10到100倍,其SQL查询比SparkSQL还要更加快速 。Impala号称是当前大数据领域最快的查询SQL工具,也因其更快的速度被市场所熟知。其面对即席查询(Ad-Hoc Query)类请求的稳定性和速度在工业界得到过广泛的验证。
我们所熟知阿里巴巴、百度、google、facebook,包括新一代的分布式计算、容器化、机器学习人工智能等技术框架都在使用Impala。Impala突破了单机技术的限制,打开了分布式技术的大门,是技术架构革命性创新的引领者。
众所周知,传统技术机构主要依赖于-IOE( IBM的小型机、Oracle数据库、EMC存储设备),只能通过增加配置提升性能,系统无法横向水平扩展。分布式存储不仅解决了单机存储的性能瓶颈,还支撑海量数据在线实时并发服务应用。
传统技术好比轿车,能承载多少人是固定的,想多承载人只能换成客车;但分布式存储技术好比火车和高铁,按节承载,遇到春运可以增加车厢运输客流量。
国产数据库产品Hubble就是这高速列车,虽不是为速度而生,却在速度上赶超Impala。
在数据体量121亿条账户下进行资金查询测试, Hubble的性能是Impala的231%倍。
之所以做这个测试,源于某证券用户在使用Hubble进行数据查询后,感叹到:这也太快了,简直比Impala还快。
Hubble,人类天眼 ,位于地球的大气层之上的光学望远镜。从1990年到2015年4月,哈勃望远镜在地球轨道上运行了接近13万7千圈,累计54亿公里,执行了120多万次观测任务,观察了超过38,000个天体,增进了人类对宇宙的了解。“哈勃遗产场”是迄今最完整最全面的宇宙图谱。
天云数据研发Hubble的初衷也非常明了,融合传统数据库形成支持混合负载交易的数据联邦。 在实际应用中,hubble完成了‘去IOE’中最困难的部分,在几家大型商业银行核心交易中成功替换Oracle,在银行的联机事务中解决A类核心系统减负问题。一句话概述,Hubble让生态合作伙伴无缝切入大数据服务领域。
在分布式的新世界里,数据从‘生产产物’变成了‘生产者’,数据身份的转换对技术、人才的需求都发生了改变。 很多企业想进入大数据服务领域,苦于人才难找、技术不行、项目周期太长、运维成本太高。这就好比一个人想写一本内容涵盖家庭装修、家庭布置、家庭关系处理的书,虽然都跟家庭有关,但具体内容却是术业有专攻,需要大量时间学习这三个方向的内容然后进行整合。但是在hubble的世界里只需调动这三个方向的专家,让他们各自撰写自己擅长的内容,然后整合到一起,专业度更有保障,出书所需时间更短。
为什么Hubble会在速度上如此有优势?
从 SQL 解析层上 ,Hubble 采用基于 AI 评估函数创建模型,在需要的时候直接调用完成目 标的预测并估算每组执行计划的代价。简单来说,就是用经验使用数据,用数据更新经验, 双管齐下速度更优。
在数据存储层上 ,Hubble 采用基于切片的列式存储和 KV 存储的混合部署模式。大数据环境下的Hbase、HP Vertica、EMC Greenplum 等分布式数据库采用的列式存储。常规行式存储下一张表的数据都是放在一起的,查询时所有数据都要被读取。但列式存储下数据被分开保存了,查询时只有涉及到的列会被读取,从而对于大表数据效率更高。KV 存储把不常变动的一些数据存储在kvstore中,需要的时候直接凭借key拿出value 就好,方便快捷就是它应对随机IO访问的优势。在大规模数据同时支持密集AP计算和TP并发场景下,基于数据切片的混布存储策略可以弹性适应IO特性,需要进一步优化时也可以快速做库内转换,避免数据复制和冗余。
在数据计算上 ,hubble是基于内存的计算框架,输出结果可以保存在内存中,减少数据的落地,后续的执行结果有依赖前面结果的可以直接从内存中获取得到,避免了磁盘的io操作,性能更高速度更快。
据IDC预测,2017-2022年,全球软分布式存储市场规模的平均增速为14.7%,而中国分布式存储市场的平均增速为32.5%。有分析师乐观地预测,未来3年,在中国市场上,分布式存储或将占据整个存储市场的半壁江山。
未来学家阿尔文·托夫勒说:“如今所有的国家都面对一个逃不了的规律—最快者生存 。”















