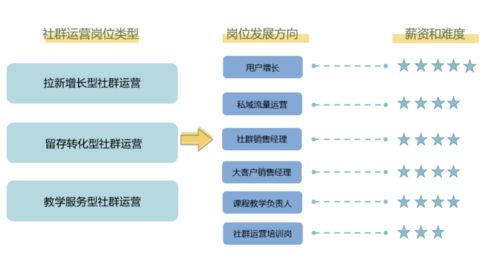
微信官方账号的回复:干货,领取58元/套IT管理系统文档。
微信官方账号回复:ITIL教材,并领取最新ITIL4语文教材。
本文的主要内容:It运维服务内容
IT运维服务流程
It运维服务管理系统规范
It运维应急服务响应措施
01
服务内容
1.1服务目标运维服务包括信息系统相关主机设备、操作系统、数据库和存储设备等信息系统的运行、维护和安全服务,保障用户现有信息系统的正常运行,降低整体管理成本,提高网络信息系统的整体服务水平。同时根据日常维护数据和记录,提供用户信息系统的整体建设方案和建议,更好地为用户的信息化发展提供有力保障。
用户信息系统的组成可以分为两类:硬件设备和软件系统。硬件包括网络设备、安全设备、主机设备、存储设备等。软件可分为操作系统软件、典型应用软件、业务应用软件等。
通过对运维服务的有效管理,可以提高用户信息系统的服务效率,协调各业务应用系统的内部运行,改善网络信息系统部门与业务部门之间的沟通,提高服务质量。结合用户现有环境、组织结构、IT资源和管理流程的特点,从流程、人员和技术三个方面规划用户网络信息系统的结构。协调用户的运营目标和业务需求与IT服务的运营目标和业务需求。
信息服务的目标是监控和管理用户现有的基础信息系统资源,及时掌握网络信息系统资源的现状和配置信息,反映信息系统资源的可用性和健康状态,营造一个可知可控的IT环境,以保证用户信息系统各业务应用系统的可靠、高效、持续、安全运行。
项目范围涵盖的信息系统资源在以下方面的关键状态和参数指标:
运行状态和故障情况
配置信息
可用性和健康性能指标
统计维度,提供信息系统管理和工作报表,汇总并提供用户想了解的数据报表。
1.2信息资产统计服务
该服务属于基本服务,包含在运维服务中。帮助我们了解用户现有的信息资产,更好地提供系统的运维服务。
服务包括:
硬件型号、数量、版本等信息的统计记录
产品型号、版本、补丁等信息的统计记录
网络结构、网络路由和网络IP地址的统计记录
综合布线系统结构图的绘制
其他辅助设备的统计记录
硬件库存统计
1.3网络和安全系统运维服务
网络系统的运维管理从网络连通性、网络性能和网络监控管理三个方面实现。网络与安全系统的基本服务内容:
用户现场技术人员值班。
根据用户需求,为用户技术人员提供长期现场服务,保证网络的实时连通性和可用性,保证接入交换机、汇聚交换机和核心交换机的正常运行。
现场技术人员记录网络交换机的端口是否可以正常使用,网络的转发和路由是否正常进行,测试交换机的性能,评估网络整体性能,优化网络的利用率,提出网络扩容和优化的建议。
现场人员还监控安全设备的日常运行状态,查看各种安全设备的日志,记录关键事件,判断和解决安全事件的原因,及时发现问题,防患于未然。
同时可以记录设备的运行数据,形成报表进行统计分析,便于网络系统的分析和故障的提前预测。记录的数据包括:
格式数据
工作特性
故障数据
现场检查服务
现场检查服务是对客户的设备和网络进行全面检查的服务项目。通过这项服务,客户可以获得设备运行的第一手资料,最大程度地发现隐患,保证设备的稳定运行。
同时会提出针对性的预警和解决方案,让客户及早防范,最大限度降低运营风险。
巡回检查包括以下内容:
操作分析和管理服务
网络运行分析和管理服务是指工程师对网络运行状况和网络问题进行定期检查和分析后,向客户提供指导性建议的综合性高级服务,其内容包括:
重要人员时刻值班。
确保设备在重要时刻的稳定运行对客户的成功尤为关键。因此,我们可以在重要时刻为客户提供现场支持,包括政府客户的重大会议、金融客户的年终结算日、运营商客户的生产网络的重大割接或客户认为可能对其业务运营产生重大影响的任何其他时刻。
如果需要有人值班,客户应至少提前3周联系授权服务提供商的客户服务经理。对于每个合同客户,授权服务提供商需要根据之前的合同协议提供专门的服务。如果客户需要更多超出合同范围的值班支持,则需要支付额外的人工和差旅费。
1.4主机和存储系统运维服务
主机和存储系统的运维服务包括:主机和存储设备的日常监控、设备运行状态监控、故障排除、操作系统维护、补丁升级等。
主机存储系统的基本服务内容:
现场人员可以监控和管理的内容包括:
CPU性能管理;
内存使用管理;
硬盘使用管理;
系统流程管理;
主机性能管理;
实时监控主机电源和风扇的使用情况以及主机机箱内部温度;
监控主机硬盘的运行状态;
监控主机网卡、阵列卡等硬件的状态;
监控主机HA的运行状态;
主机文件系统管理;
监控存储交换机的设备状态、端口状态和传输速度;
监控备份服务流程和备份情况;

监控磁盘阵列、磁带库等存储硬件的故障提示和告警,及时解决故障问题;
监控存储的性能。
1.5数据库系统运行和维护服务
数据库运维服务包括主动数据库性能管理,这对系统运维非常重要。通过主动的性能管理,可以了解数据库每天的运行状态,识别数据库性能问题出在哪里,有针对性地进行性能优化。同时密切关注数据库系统的变化,主动预防可能出现的问题。
数据库运维服务还包括快速发现、诊断和解决性能问题,在问题发生时及时发现性能瓶颈,解决数据库性能问题,维护高效的应用系统。
数据库运维服务,主要工作是利用技术手段实现管理目标,以系统的最终运维为目标,提高用户的工作效率。
数据库操作、维护和监控的基本服务包括:
1.6中间件运维服务
中间件管理是指对BEA Weblogic、MQ等中间件进行日常维护、管理和监控,以提高分析和解决中间件平台事件的能力,保证中间件平台的持续稳定运行。中间件监控指标包括配置信息管理、故障监控和性能监控。
执行线程:监控WebLogic配置执行线程的空闲数量空。
JVM的内存:JVM的内存曲线是正常的,可以及时回收内存空。JDBC连接池:连接池的初始容量和最大容量应该设置成相等,并且至少等于执行线程的数量,以避免在运行过程中创建数据库连接所造成的性能消耗。
检查WEBLOG日志文件中的异常错误。
如果有WEBLOG集群配置,需要检查集群配置是否正常。
02
运维服务流程
建议用户采用两种服务模式:一种是技术人员上门服务,另一种是定期检查结合故障上门服务。技术人员现场运维服务的基本操作流程如下图所示:
定期检查结合故障现场运维服务的基本操作流程如下图所示:
03
服务管理系统规范
3.1服务时间接受服务请求和咨询:5*8小时设立专人热线,接听内部服务请求,记录服务台事件处理结果。
有手机热线,非工作时间7*24小时专人接听,用于解决内部技术问题,7*24小时接听机房监控人员机房紧急报告。
响应时间:
在解决故障时,技术人员会最大限度地保护数据,准备好故障恢复的文档,力争恢复到故障点前的业务状态。
对于“系统瘫痪,业务系统无法运行”的故障级别,如果12小时内无法解决故障,将在16小时内提出应急预案,保障业务系统运行。故障解决后24小时内,提交故障处理报告。解释故障的类型、故障的原因、故障排除中使用的方法以及故障的损失。
3.2行为准则
遵守用户的规章制度,严格按照用户相应的规章制度办事。
与用户运维系统其他部门和环节合作,密切配合,共同开展技术支持工作。
遇有疑难技术和业务问题及重大突发事件,及时向负责人报告。
现场技术支持应精神饱满,衣着得体,言语文明,举止庄重。接电话的时候,要有礼貌,说话要清晰亲切。
遵守保密原则。对被支持单位的网络、主机、系统软件和应用软件的密码、核心参数和业务数据负责保密,不得随意复制和传播。
3.3现场服务支持规范
运维人员要有耐心,细心,热情。工作中要做好记录,有反馈,重大问题及时汇报。严格遵守工作时间表,严格按照服务流程操作。
现场支持工程师应着装整洁,举止礼貌大方,技术专业,操作熟练、严谨、规范;现场支持必须遵守使用单位的相关规章制度。
现场支持工程师在开展现场支持工作时,必须在确保数据和系统安全的前提下工作。
如现场出现暂时无法解决的故障或其他新的故障,应及时通知用户并向负责人汇报,寻找其他解决方法。
故障解决后,现场支持工程师应详细记录问题的发生时间、地点、提出者和描述,并形成书面文件。必要时,现场支持工程师应向用户介绍故障原因、预防方法和解决方案。
3.4问题记录规范
根据用户提出的问题类型,问题可以分为两类:咨询问题和系统缺陷问题。咨询问题是指用户提出的可以通过服务热线或现场故障排除当场解决的问题,具有直接、快速、实时解答的特点。问题可以在现场支持人员处停止,此类问题的记录可以通过咨询问题记录模板进行记录。系统缺陷问题是指用户提出的涉及系统相应环节的确认和修改,需要逐级提交、诊断、确认、处理和回复的问题。解决方案需要项目组的分析和确认,问题有解决方案后会反馈给用户。具体提交流程如下:
问题提交。信息系统用户发现属于系统缺陷的问题时,填写《系统缺陷问题提交表》,提交给服务支持中心。
问题分析。服务中心收到用户提交的问题单后,应组织相应人员对问题单中描述的问题进行分析判断,确定问题类型。
属于技术问题,提交服务中心技术人员对存在的问题提出具体处理意见和建议;如果是业务问题,提交服务中心业务人员处理;如遇运营问题,可安排相关人员对问题提出者进行说明,并将《系统缺陷问题提交单》转换为《系统咨询问题提交单》。
确认和解决问题。服务中心技术和业务人员收到《系统缺陷问题提交表》后,应对提交的问题进行分类、汇总、分析和确认。
如能解决,明确解决问题的具体建议和措施,经主管领导签字同意后,提交给实施者实施。服务人员确认是否解决问题,并将解决方案附在《系统缺陷问题提交表》中反馈给问题提出者。
问题升级。服务人员收到业务或技术人员确认的系统缺陷问题提交单后,向服务中心报告。
回答问题。服务中心应对提交的问题进行分析,制定解决方案并实施,做好变更记录。汇总解决方案后,及时回复问题提交单位或问题交办单位,一并提交问题的分析过程和原因。
04
应急服务响应措施
项目制定了详细的设计和应急预案,整个过程严谨有序。但是,在服务维护过程中,意外情况将很难完全避免。下面,我们将对项目实施过程中的突发风险进行详细分析,针对各类突发事件设计相应的防范和解决措施,并提供完整的应急处理流程。
4.1基本应急流程
4.2预防措施
针对现场服务过程中可能遇到的各种风险,针对一些可能出现的情况制定了一系列防范措施,例如:
4.3突发事件的应急响应策略
系统运维应急预案是对停机、数据丢失、业务中断等中断或严重影响业务的故障进行快速响应和处理。,从而在最短的时间内恢复业务系统,将损失降到最低。
在系统维护过程中,突发事件的出现将很难完全避免。针对这种情况,设计了完善的应急响应策略。
系统巡视人员要定期检查硬件设备和应用软件的运行情况,做好每日增量数据备份和定期完整备份。

将发现的问题向各级负责人汇报时,要协调相关资源分析问题根源,确定解决方案和临时解决方案,避免造成更大影响。待问题稳定或完全解决后,要形成问题报告,避免今后类似重大突发事件的发生。
发现的问题向负责人汇报时,要协调相关资源分析问题根源,确定解决方案和临时解决方案,避免造成更大影响。待问题稳定或完全解决后,要形成问题报告,避免今后类似重大突发事件的发生。
当了解到紧急情况时,技术支持人员可以立即从知识库中获取相应的应急策略,并根据用户的具体情况给出相关的解决方案。然后,他们可以在第一时间通过电话、电子邮件支持或现场服务来帮助用户解决问题,并尽最大努力减少突发事件对用户日常应用的影响。
应急策略服务流程图如下:
完整文档下载链接https://www.itilzj.com/doc-255859.html